Parallelism with Java Streams and CountedCompleter :: Dec 28, 2019
Parallel processing is an optimization. So if a problem demands parallelization, you should make sure the computational model is as performant as possible.
This leads to my claim:
> Parallel processing is problem-dependent, while Parallel Streams are general.
Parallel Streams are based on CountedCompleter in class AbstractTask, and does a reasonably good job in non-blocking parallel workloads. But by exploiting the shape and properties of the problem, performance can be significantly improved.
- Big Ideas: what are ForkJoinPool, ForkJoinTask, and CountedCompleter?
- Optimizing CountedCompleter
- Benchmarks
- Conclusion & Benchmark Source
Big Ideas
Java's Fork-Join Framework (ForkJoinPool, ForkJoinTask, CountedCompleter) is superior to thread pools for non-blocking parallelism, thanks to work-stealing and recursion. Refer to the JavaDoc for performance characteristics vs standard thread pools. ForkJoinTask subclasses like RecursiveAction, RecursiveTask, and CountedCompleter are submitted to the ForkJoinPool, and either recursivly split off new tasks, or execute some computation. Of the three concrete ForkJoinTasks, CountedCompleter is the most efficient, since it avoids the blocking `join()` by providing its own continuations. And while CountedCompleter is somewhat less straightforward to program, it is not as conceptually challenging as the JavaDoc would suggest.
Consider a simple map-reduce operation done over a large array:
long res = 0;
for (int i : array)
if (i < 150)
res += fnv(i) % 5;
Here, we iterate over the array, filter the elements so that all are less than 150, map `i` to the Fowler-Noll-Vo hash function reduced to a bucket size of 5, and then added to `res`. We can use `res` to estimate the effectiveness of the hash function & reduction.
The parallel streams version is:
Arrays.stream(arr)
.parallel()
.filter(i -> i < 150)
.mapToLong(i -> fnv(i) % 5)
.sum();
And such a task can be easily parallelized with CountedCompleter. First, we create the initial task:

Which spawns two sub-tasks and increments the volatile pendingCount by 2:

And again, until we reach the desired number of sub-tasks (next section discusses optimal choice):

Lets say we stop splitting here, when the elements-per-leaf is 250. When a task completes it decrements its own pending count, but if the pending count is already zero, then the parent's pending count is decremented if possible. By chance, task B0 is completed first. Its pending count is already zero, so B0's `onCompletion` method is called and task B's pending count is decremented:

Next, it happens that task B1 finishes. B's pending count is decremented. Since B was only waiting for its children to complete, any thread can now finish execution of B, which results in decrementing A's pending count. And so on:

When the root task's pending count reaches zero and the final `onCompletion` is called, the job is effectively completed.
Optimizing CountedCompleter
The graph above is close to what java.util.Stream's AbstractTask accomplishes. But because we operate on an array of fixed size, there are several optimizations that can be employed. First, consider the target number of tasks. It's reasonable to set a value like 4 * #cores, like in AbstractTask. But some problems may benefit from more, especially if the processing time is irregular. But on the flip side, more sub-tasks means more allocations and greater framework overhead. So it's not a good idea to spawn a task per array item. Additionally, if many jobs are being submitted to the same pool, ForkJoinTask::getSurplusQueuedTaskCount can be used to dynamically decide whether to spawn sub-tasks. For this implementation, we'll stick to 4 * #cores.
Another factor to consider is the minimum number of operations per 'leaf' sub-task. If you only have 16 array elements and four cpu cores, it will probably be faster to just processes all elements on a single core, rather than giving four to each core. The Fork-Join authors recommend a ops/leaf minimum between 1,000 and 10,000. Since the fnv map-reduce is so simple, I'll use 10,000.
The biggest improvement is when we realize that the 'node' tasks don't perform useful computation, but only spawn and wait for other sub-tasks. And because every node spawns a maximum of only two sub-tasks, this means that there's a large amount of work-stealing contention early on, as threads compete for a small number of tasks (that don't perform useful computation). AbstractTask does the former, but not latter, because it must be general. Let's rearrange our graph.
From the root node, we keep dividing the array by two and forking sub-tasks until the target size is reached. If the array is size 1,000, and the target is 250, we have this graph initially:

After the first fork:

Task A is still not at the target size, so fork again:

And when `compute` in task B is called, we fork B, once again adjusting the parent's range:

We can even compute the pending count in advance! Let the variable totaltasks be the total number of tasks spawned, equal to array length / `MIN_SIZE_PER_LEAF`. Then the root task spawns pending = log2(totalTasks) direct sub-tasks. The first subtask spawned by the root will in turn fork pending - 1 subtasks. The second subtask spawned by the root will fork pending - 2 subtasks, and so on, with each ith sub-task forking pending - i subtasks, where pending is the total number of subtasks forked by its parent. This can easily be seen by drawing out a larger graph, and is implemented in `computeInitialPending`. The full CountedCompleter sub-class is only 66 lines long:
static final class CustomCC extends CountedCompleter {
private static final int TARGET_LEAVES =
Runtime.getRuntime().availableProcessors() << 2;
// ie, every leaf should be process at least 10_000 elements
private static final int MIN_SIZE_PER_LEAF = 10_000;
private static int computeInitialPending(int size) {
// if x = size / MIN_SIZE_PER_LEAF, and x < TARGET_LEAVES,
// create x leaves instead. This ensures that every leaf does
// at least MIN_SIZE_PER_LEAF operations.
int leaves = Math.min(TARGET_LEAVES, size / MIN_SIZE_PER_LEAF);
// If the total # leaves = 0, then pending = 0 since we shouldn't fork.
// Otherwise, pending = log2(leaves), as explained in the doc
return leaves == 0
? 0
: 31 - Integer.numberOfLeadingZeros(leaves);
}
final int[] arr;
int pos, size;
long res = 0;
final CustomCC[] subs;
public CustomCC(int[] arr) {
this(null, arr, arr.length, 0, computeInitialPending(arr.length));
}
private CustomCC(CustomCC parent, int[] arr, int size, int pos, int pending) {
super(parent, pending);
this.arr = arr; this.size = size; this.pos = pos;
subs = new CustomCC[pending];
}
@Override
public void compute() {
// subs.length === getPendingCount()
for (int p = subs.length - 1; p >= 0; --p) {
size >>>= 1;
CustomCC sub = new CustomCC(this, arr, size, pos + size, p);
subs[p] = sub;
sub.fork();
}
// needed for c2 to remove array index checking...
// modified from Spliterator class
int[] a; int i, hi;
if ((a = arr).length >= (hi = pos + size) && (i = pos) >= 0 && i < hi) {
do {
int e = a[i];
if (e < 150) res += fnv(e) % 5;
} while (++i < hi);
}
tryComplete();
}
@Override
public void onCompletion(CountedCompleter caller) {
for (CustomCC sub : subs) res += sub.res;
}
@Override
public Long getRawResult() {
return res;
}
}
Benchmarks
Running on a 40 thread Xeon E5-2660 v3 @ 2.60GHz, we see the following results for a random array of size 50 million
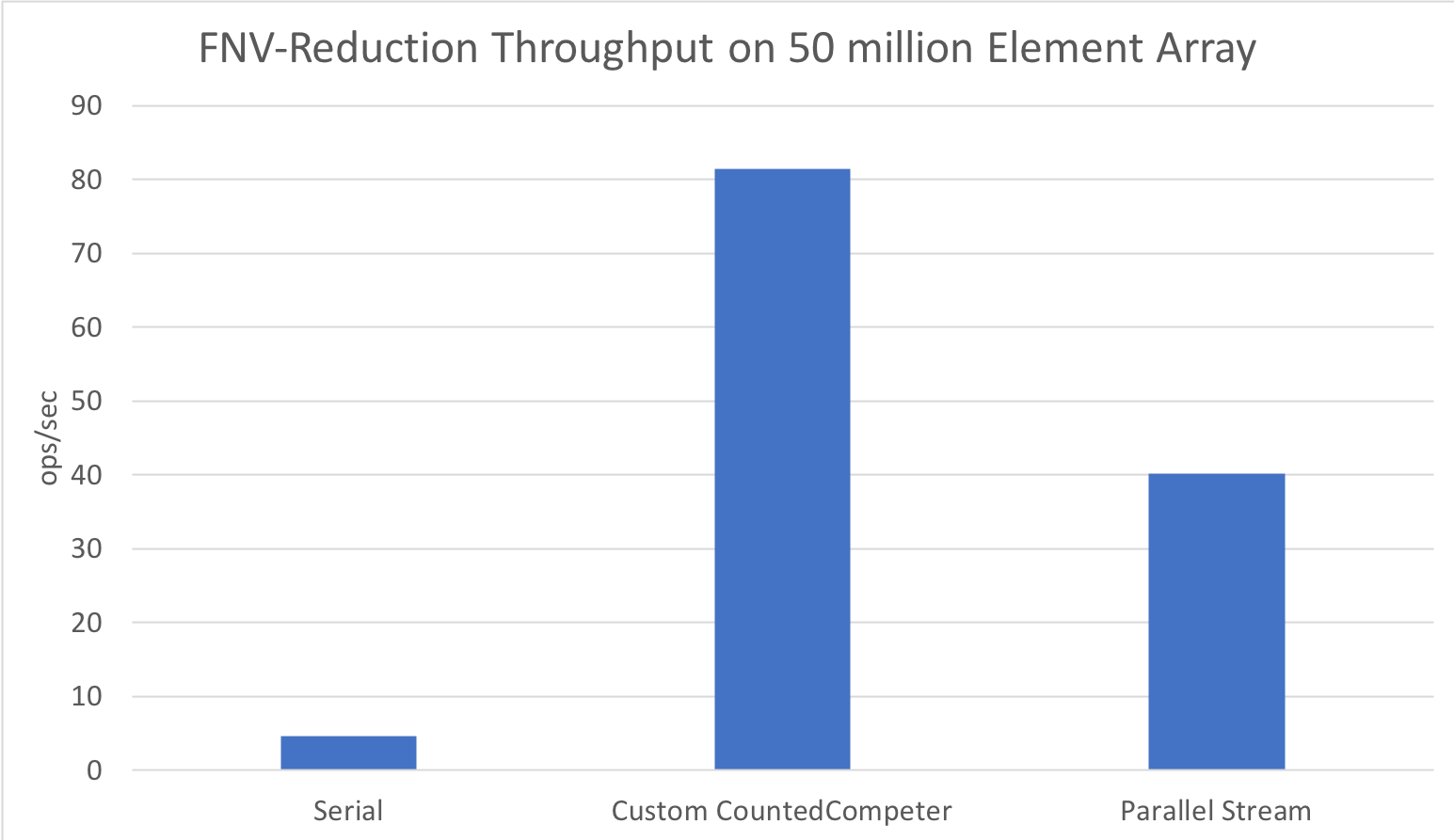
Performance similarly holds for small arrays, since we consider the minimum elements per leaf:
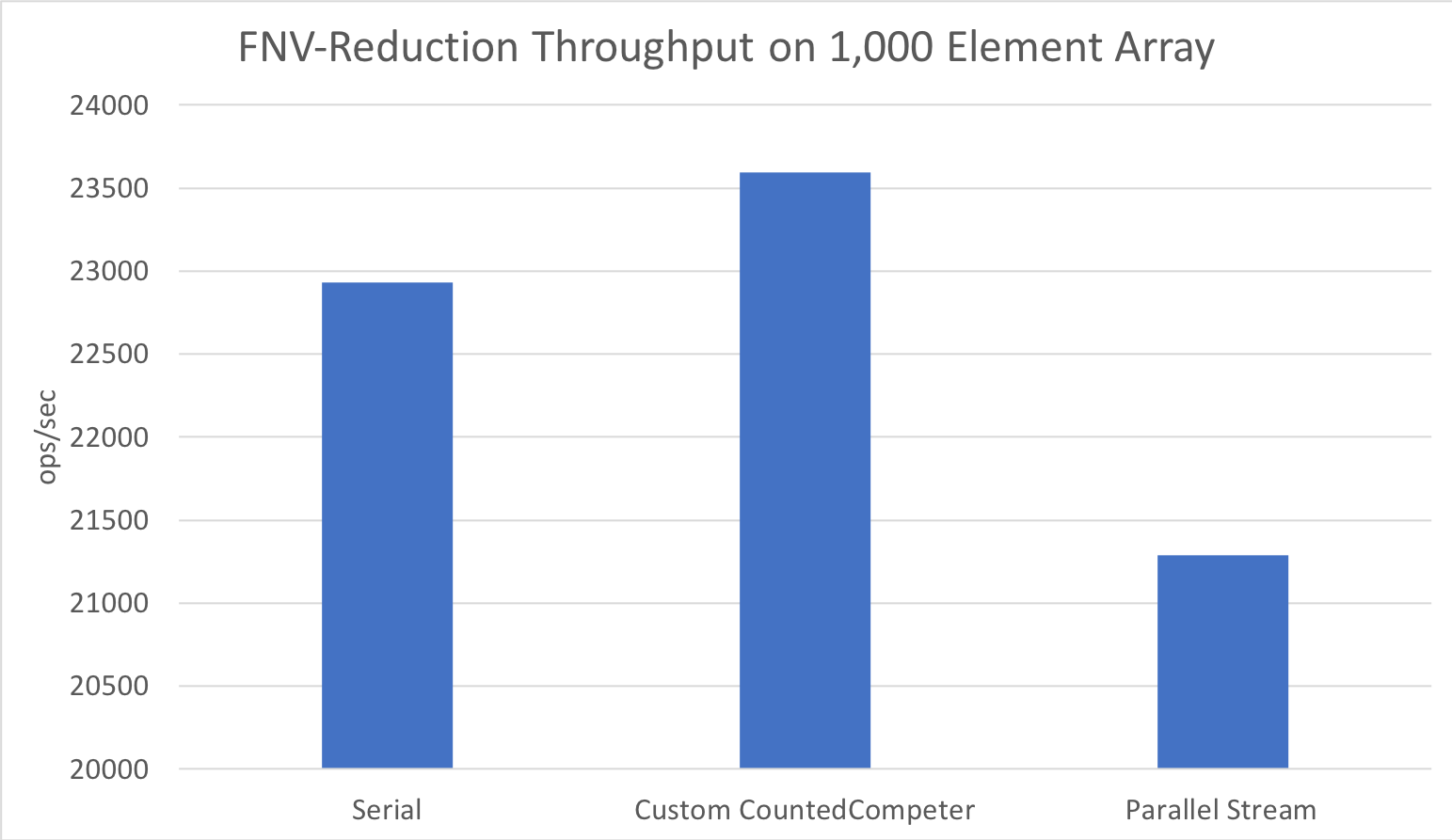
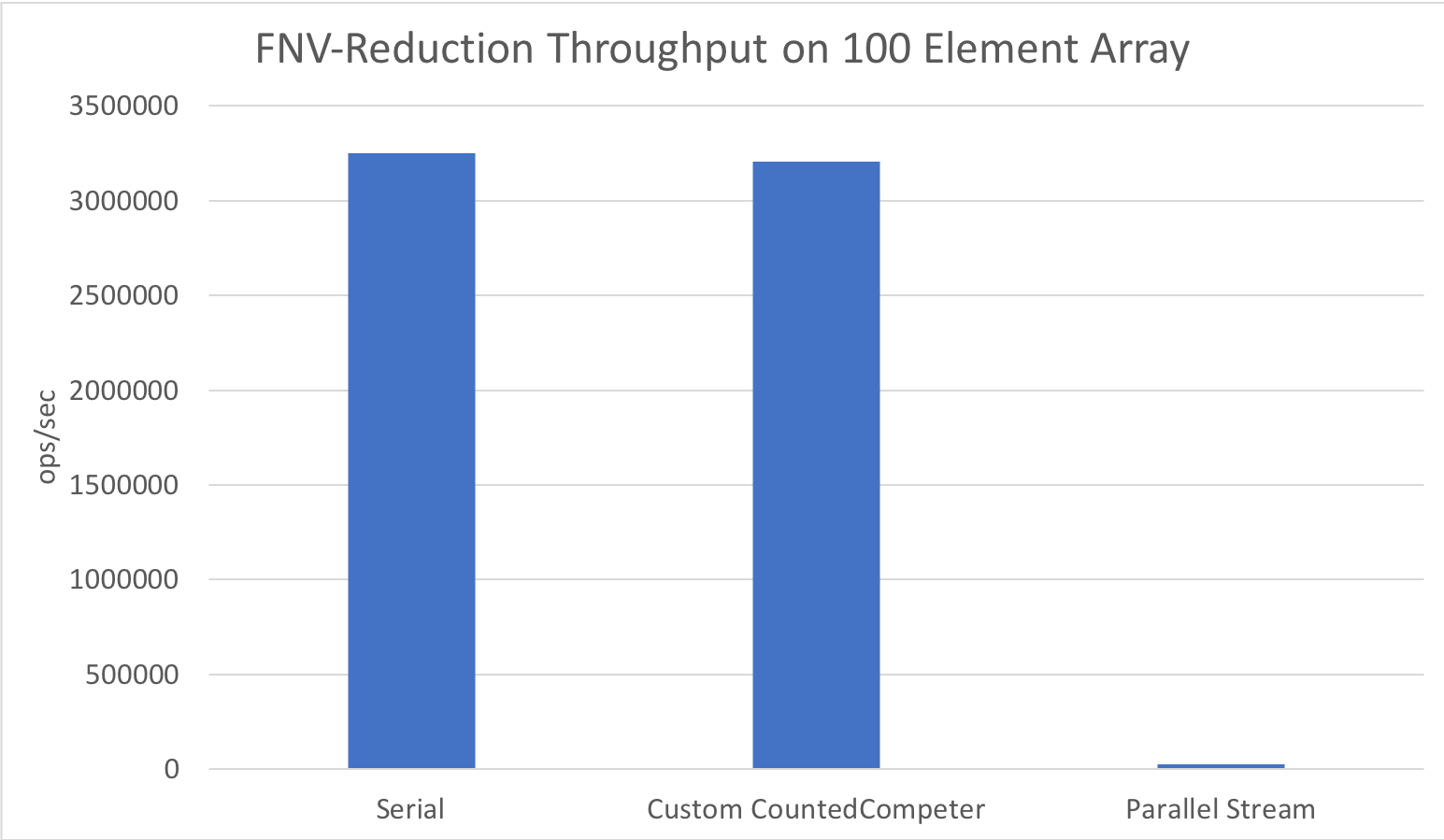
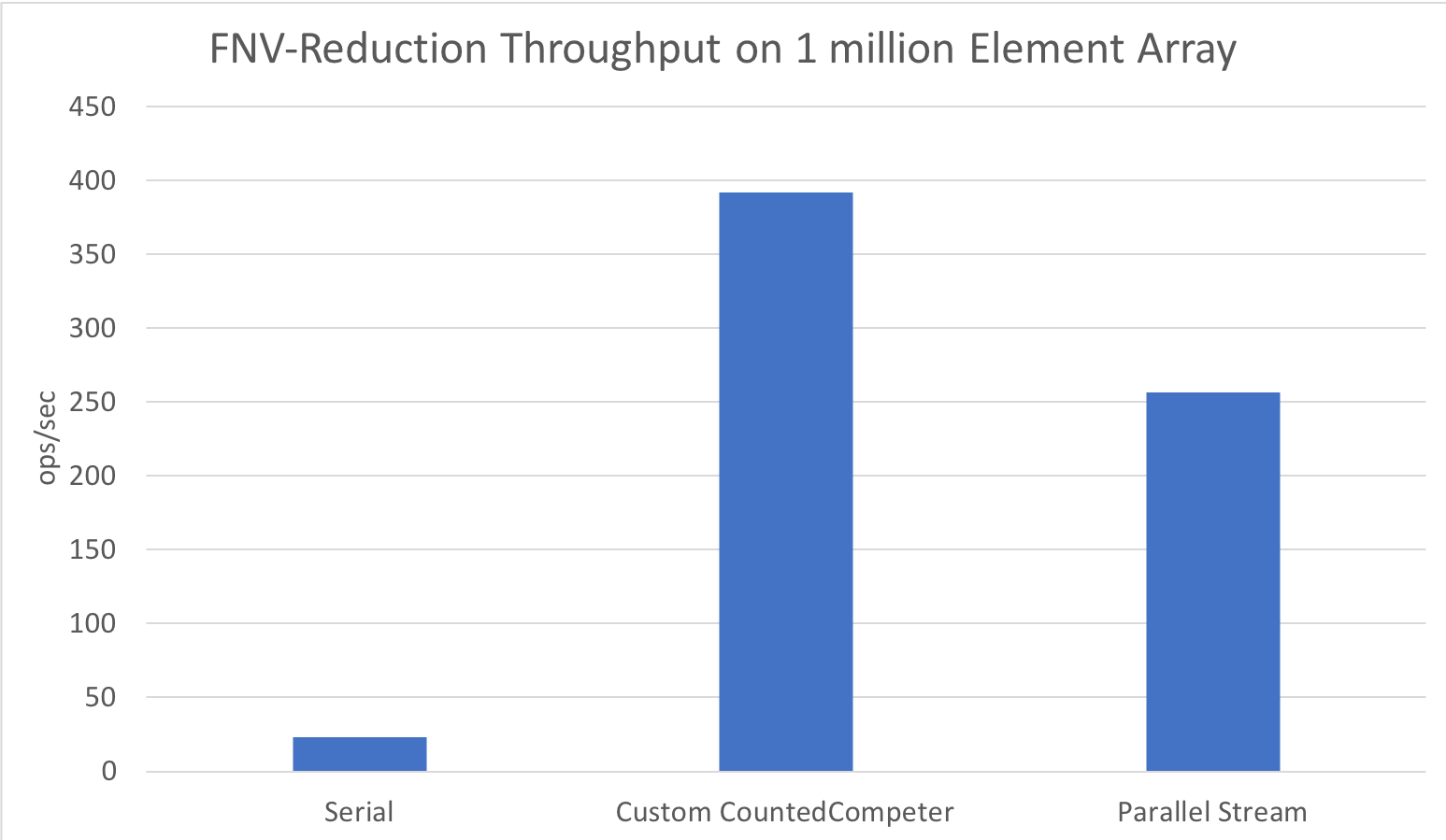
And at a few more sizes:
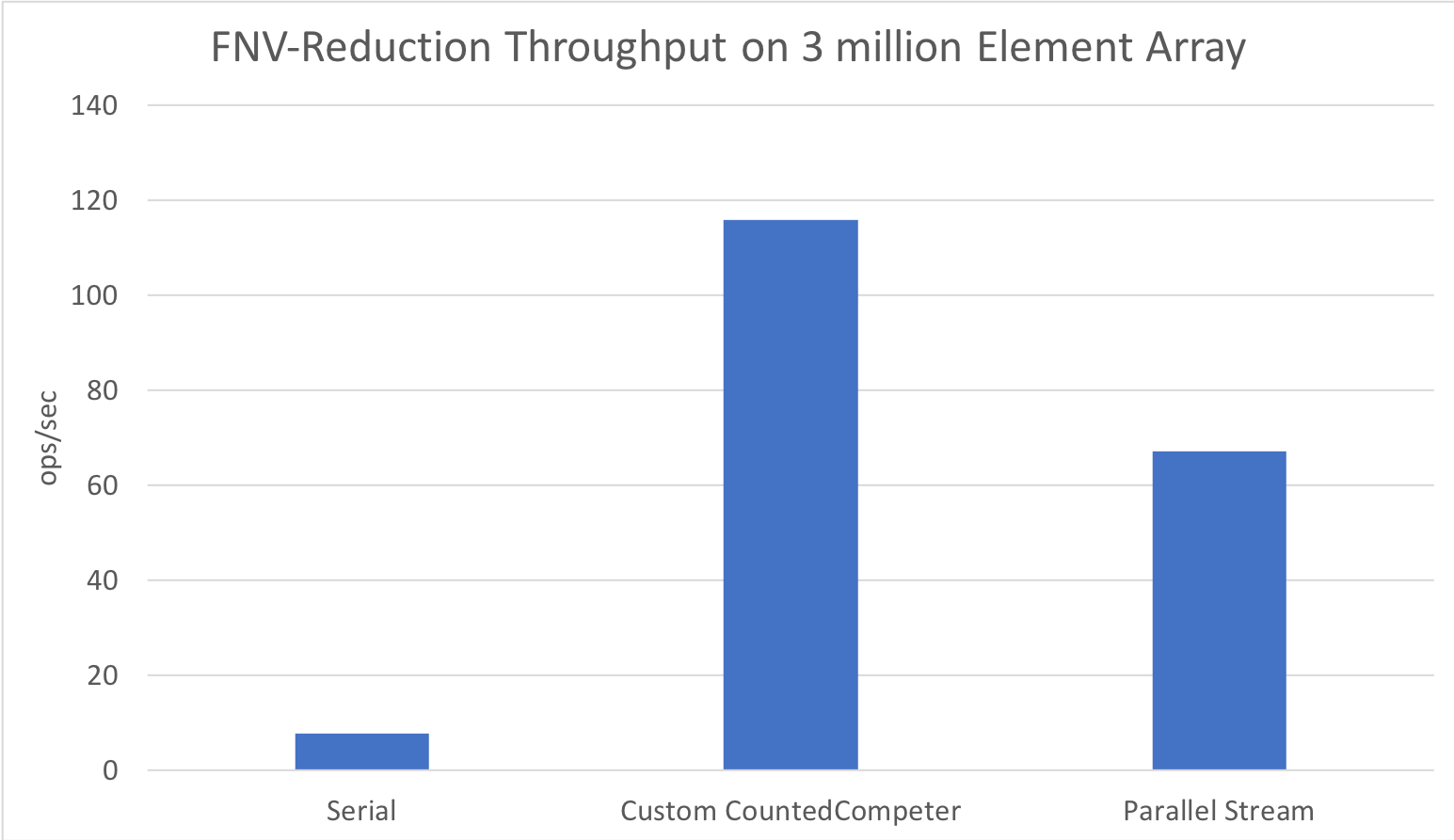
Conclusion
Don't use parallel streams, unless for prototyping or one-off jobs... a tailored CountedCompleter sub-class is simply better!